Using the GitHub REST API to fetch and display gists
Authenticating with the GitHub API, enabling cross-domain Ajax fetching with CORS, implementing a basic caching system, installing a custom npm dependency, and more.
I wanted to add some additional content to my home page: stuff that didn’t merit a blog post but which I thought was still worth sharing. I’d already been using GitHub Gist to record code snippets and other notes, so decided to look into using the GitHub REST API to retrieve that data and display it on the page.
tl;dr: if you’d rather just dig into the code, and not bother with this blog post, there’s a repo on GitHub.
This post describes a demo version — available at the repo linked above — of the code I deployed on my home page.
Contents permalink
Testing the API permalink
You can query the API to fetch a list of gists for a specific user without authenticating. For example, running this code in your browser console will return a listing of my 15 most recent gists in JSON format (optionally replace donbrae with your own user name):
fetch('https://api.github.com/users/donbrae/gists?per_page=15').then(response => {
// Success
if (response.ok)
return response.json(); // Returns to then()
// Error
return Promise.reject(response);
}).then(data => {
console.log(data);
}).catch(err => {
console.error(err); // Error
});You can also fetch the actual content of a gist by using the /gists/{gist_id} endpoint, eg https://api.github.com/gists/d78ee08d2ffdc2f7b8442155f9cf7fa1.
Authenticating permalink
For unauthenticted users, the API is rate-limited to 60 requests per hour. Creating a personal access token1 and using it to authenticate with the API gets you 5,000 an hour.
When authenticating, we don’t want to expose the access token by making the request directly on the client side, so we can set up proxy scripts on a server to do the authenticating and make the API calls.
I wrote the scripts in PHP because I have some familiarity with the language, and it comes installed with your typical web hosting plan, but you can translate it to your preferred language.
Proxy scripts permalink
The two proxy scripts — one to fetch the list of gists, and one to fetch a particular gist’s content — are in the repo donbrae/get-gists.
header.inc permalink
header.inc contains code we’ll use in both scripts. First we add headers to set the Content-Type to application/json (we’ll be serving JSON), and the Cache-Control header to no-cache (we’ll be implementing our own caching system).
<?php
header('Content-Type: application/json');
header('Cache-Control: no-cache');Next, the variable $opts contains our HTTP context options, including the request header values we’ll pass to the GitHub API. Replace <token> with your personal access token.
$opts = [
'http' => [
'method' => 'GET',
'header' => [
'User-Agent: PHP',
'Content-Type: application/json',
'Accept: application/vnd.github+json',
'Authorization: token <token>'
]
]
];There is also a function that writes files in a way that avoids potential write conflicts:
function writeFile($filename, $content, $append = false) {
// https://softwareengineering.stackexchange.com/a/332544
$unique_tmp_filename = uniqid('', true) . '.tmp'; // Create unique filename
if ($append) {
file_put_contents($unique_tmp_filename, file_get_contents($filename) . $content); // Concatenate contents of existing file with new content
} else {
file_put_contents($unique_tmp_filename, $content);
}
rename($unique_tmp_filename, $filename);
}And a function to parse the response headers:
function getResponseHeaders($http_response) {
// https://beamtic.com/parsing-http-response-headers-php
$response_headers = [];
foreach ($http_response as $value) {
if (false !== ($matches = explode(':', $value, 2))) {
$response_headers["{$matches[0]}"] = trim($matches[1]);
}
}
return $response_headers;
}And, finally, a function to get the HTTP response status code as an integer:
function getStatus($http_response) {
// https://stackoverflow.com/a/52662522/4667710
$status_message = array_shift($http_response);
preg_match('{HTTP\/\S*\s(\d{3})}', $status_message, $match);
$status = intval($match[1]);
return $status;
}
?>(You probably won’t need the last two functions if you’re not using PHP. PHP is weird.)
fetch.php: fetch a listing of gists for a user permalink
Now onto the script that will actually get the data, fetch.php.
We start by including the header.php file:
<?php
require_once 'header.inc';Next, name a file that we’ll use as a cache:
$cache_file = 'cached.json';Now we’ll call the API and store the returned data in variable $content:
$context = stream_context_create($opts);
$content = file_get_contents('https://api.github.com/users/donbrae/gists?per_page=15', false, $context);We’ll then use a couple of the other functions we declared in header.php to parse out the response status code and headers. This data is available in the $http_response_header array:
$status = getStatus($http_response_header);
$response_headers = getResponseHeaders($http_response_header);If the status is 200, we output the JSON returned from the API:
if ($status === 200) {
echo $content;Next we add a conditional that checks the X-RateLimit-Remaining response header to determine whether we should write a copy of the returned JSON to our cache file:
if (
intval($response_headers['X-RateLimit-Remaining']) < 250 && // We may hit the API rate limit soon
file_exists($cache_file) && (time() - filemtime($cache_file)) / 60 / 60 > 6 || // Cached file hasn’t been updated in last 6 hours
!file_exists($cache_file) // Or there is no cache file
) {
writeFile($cache_file, $content); // Write a cached version of JSON in case API rate limit is reached
}I set the threshold to an arbitrary 250 API calls remaning. The conditional could instead in theory be X-RateLimit-Remaining === 0, but the script that fetches the actual gist content (fetch-id.php) also counts towards API usage, so we can’t guarantee that fetch.php will be called when the rate limit is exactly zero.2
There is also a condition which checks that the cache file hasn’t been updated in the last six hours, to avoid continually writing a new cache file every time this script is called and X-RateLimit-Remaining is under 250.
Alternatively, if no cache file exists — regardless of other conditions — write one.
If another status is returned, and if there is a cached version, serve the cached version; otherwise, return an error message in JSON format:
} else if (file_exists($cache_file)) { // Status ?304, 403 or 422
echo file_get_contents("cached.json"); // Serve cached copy
} else {
echo "{\"error\": \"Cannot fetch list of gists. Error code: $status\"}";
}
?>CORS permalink
Add fetch.php to your server in a folder called gists. If you’re using another domain to host the proxy scripts — as I’m doing because my blog is a static site hosted on Netlify, which doesn’t support PHP — we’ll need to make sure Cross-Origin Resource Sharing (CORS) is set up properly. We need to tell our server hosting fetch.php to accept Ajax requests from our originating domain. In my case, the proxy domain — donbrae.co.uk — needs to accept requests from browsers viewing jamieonkeys.dev.
To do this — and assuming your server runs Apache — add a .htaccess file in the gists folder on donbrae.co.uk:
<IfModule mod_headers.c>
Header set Access-Control-Allow-Origin: https://www.jamieonkeys.dev
</IfModule>
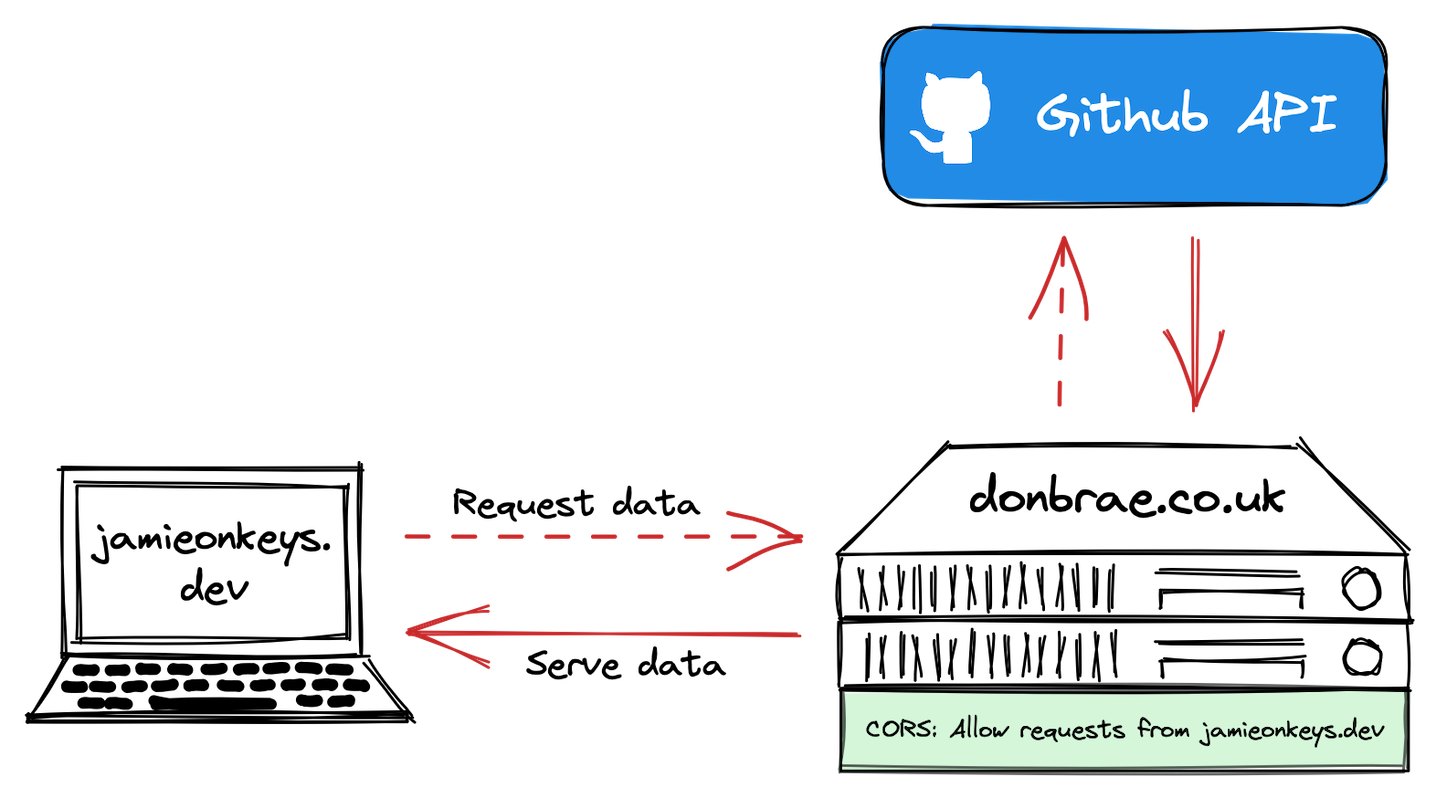
The website at jamieonkeys.dev should now be able to call https://donbrae.co.uk/proxy-php/gists/fetch.php and get the data in return.
fetch-id.php: fetch content of a specific gist permalink
There is also a proxy script, fetch-id.php, to get the content of specific gists.
Again, we start by including the same header.inc file we used previously:
<?php
require_once 'header.inc';On the front end we’ll be passing a gist ID in the querystring parameter gist_id, so capture that:
$gist_id = $_GET['gist_id'];The GitHub API returns a status code of 304 for gists which haven’t been updated since a specified date. Requests which result in a 304 also don’t count towards your rate limit. We’ll create a caching system to return static JSON files from our server so we don’t need to keep calling the API.
Add a subfolder called on your server under gists called gistscache.
fetch-id.php continues:
$cached_file_path = "./gistscache/$gist_id.json";
$cached_file_exists = file_exists($cached_file_path);
if ($cached_file_exists) {
// Get last updated date of file in GMT
$last_modified = filemtime($cached_file_path); // Get its last modified date
$last_modified_gmt = gmdate('D, d M Y H:i:s', $last_modified) . ' GMT'; // Format it so GitHub API accepts it in header
// Add date to header so that API will return 304 if no updates have been made, and we can serve the cached copy; otherwise we can expect a 200 with the latest data
array_push($opts['http']['header'], "If-Modified-Since: $last_modified_gmt");
}fetch-id.php always checks for a cached copy of the requested gist in the gistscache folder, and if one exists, gets the file’s last modified date and adds it to the headers we’ll pass to the GitHub API.
If the gist has been updated since that date, a status of 200 will be returned along with the latest data. If the gist hasn’t been updated, a 304 will be returned and we’ll serve the cached data.
Next we make the API call and store the status code:
$context = stream_context_create($opts);
$content = file_get_contents("https://api.github.com/gists/$gist_id", false, $context);
$status = getStatus($http_response_header);Add then we handle the API response:
if ($status === 200) {
echo $content; // Serve JSON returned from API
writeFile($cached_file_path, $content); // Add/update cached copy
} else if (
$status === 304 && $cached_file_exists || // Not modified and we have a cached version
$status === 403 && $cached_file_exists // We've likely reached our API limit (403 == Forbidden Gist)
) {
echo file_get_contents($cached_file_path); // Serve cached copy
} else {
echo "{\"error\": \"Cannot fetch gist. Error code: $status\"}";
}If we get a 200 — meaning the gist has been updated since the last updated date we sent in the request headers — serve the returned JSON and write a copy to the cache. If we get 304 — meaning the gist hasn’t been updated — serve a cached copy. If we get a 403, it means we’ve reached our API limit, so also serve the cached copy. In any other case, serve an error message in JSON format.
Folder structure permalink
In summary, the gists folder on your proxy server should look something like this:
.
├── .htaccess
├── cached.json
├── fetch-id.php
├── fetch.php
├── gistscache
│ ├── 0276d43b831af40d1bbe529549a66f84.json
│ ├── 2277dd0362789957fd5ce9ed4894c93b.json
│ ├── 35841f68de35bce70ea1bb4cd71ac5d1.json
│ └── [etc.]
└── headers.incBuilding the front end permalink
If you’ve not done so already, grab the code for the front end by cloning get-gists on your local machine:
git clone https://github.com/donbrae/get-gists.gitcd into the get-gists folder and run npm install.
Next, start a local server with npm run start. The page should open in your default browser.
Let’s dig into the code.
Installing a custom build of highlight.js as a npm dependency permalink
We use highlight.js to add syntax highlighting to gists that contain code. By default highlight.js is over 1 MB in size, so to minimise the amount of JavaScript we serve to the user, I created a custom build with only the languages I need, namely JavaScript, HTML, CSS, PHP and Markdown.
You’d normally install highlight.js from the public npm registry via npm install highlight.js, but I instead followed these steps:
cdto your development folder and clone thehighlight.jsrepo:git clone https://github.com/highlightjs/highlight.js.gitcd highlight.jsnpm install- Run a build for just the languages we need:
node tools/build.js javascript xml css php markdown(xmlincludes HTML) - The files we create are in
./build. Runls -l ./buildto list them cdto the root of the project folder you want to use the custom build with (in my case,get-gists)mkdir srcto create asrcfoldermkdir src/highlight.jsto create a folder for thehighlight.jscustom buildcd src/highlight.js- Use
cpto copy over the custom build we created in step 4, egcp ../../../highlight.js/build/highlight.js ./ - Run
npm initto set the folder up as an npm dependency - Answer the prompts. Call it
highlight.jsand make sureentry pointis set tohighlight.js(it should be auto-selected) cd ../..to root of your project folder- Run
npm install ./src/highlight.js - You should now see
highlight.jsreferenced as a dependency in your project’s mainpackage.json:grep --color=always -e "^" -e "highlight.js" package.json highlight.jscan now be imported from within a JavaScript file in your project:import hljs from "highlight.js";
index.html permalink
You’ll see in the repo that index.html is a basic HTML page with a button — which, when clicked, will initiate a fetch() of the gist data — and an empty <div> where we’ll add the returned data. We also include the main script, index.js:
<!DOCTYPE html>
<html>
<head>
<title>Get gists</title>
<meta charset="UTF-8" />
</head>
<body>
<h1>Get gists demo</h1>
<button id="get-gists">Get gists</button>
<div id="gists" class="hide fade"></div>
<script src="src/index.js" type="module"></script>
</body>
</html>index.js permalink
Note that, here, the two fetch calls we make call the GitHub API directly, but in production these can be swapped for the proxy URLs.
First in index.js we import our CSS files and JavaScript modules:
import './styles.css';
import './xcode.css';
import hljs from 'highlight.js';
import markdownit from 'markdown-it';styles.cssis some basic CSS for styling the page that lists the gistsxcode.cssis a set of CSS classes that style the code to look like Apple’s Xcode IDEhighlight.jsis our custom build of the code-highlightling modulemarkdown-ittransforms gists written in Markdown to HTML
Next we define a couple of functions. For security reasons, escapeHtml() sanitises any HTML that is returned by the API, replacing certain characters with their HTML entity equivalents:
// https://stackoverflow.com/a/6234804
function escapeHtml(unsafe) {
return unsafe
.replaceAll('&', '&')
.replaceAll('<', '<')
.replaceAll('>', '>')
.replaceAll('"', '"')
.replaceAll("'", ''');
}show() handles element fade-ins:
function show(el) {
el.classList.remove('hide');
setTimeout(() => {
el.classList.add('show');
}, 30);
}Next, the cfg object defines various properties, such as the GitHub user account we’re fetching gists for, and the IDs of any gists we wish to exclude from our listing:
const cfg = {
githubUser: 'donbrae',
hideIds: [
// IDs of Gists to exclude from page
'2369abb83a0f3d53fbc3aba963e80f7c', // PDF page numbers
'bfbda44e3bb5c2883a25acc5a759c8fc', // Bootstrap 5 colour gradient
'ab4e15be962602b1bf4975b912b14939' // Apple Music shortcuts
],
perPage: 15, // Number of gists to fetch from API
gistsLimit: 10 // Maximum number of gists to add to page
};So that we can display the name of the month next to each gist, we define an array of month name abbreviations:
const months = ['Jan', 'Feb', 'Mar', 'Apr', 'May', 'Jun', 'Jul', 'Aug', 'Sep', 'Oct', 'Nov', 'Dec'];Next, we have a regular expression to parse text for URLs so we can turn them into links:
const urlRegEx = /(\b(https):\/\/[-A-Z0-9+&@#%?=~_|!:,.;]*[-A-Z0-9+&@#%=~_|])/gi; // Only transform https URLs. Source: https://www.codespeedy.com/replace-url-with-clickable-link-javascript/We also grab the HTML element into which we’ll place the returned gists:
const gists = document.getElementById('gists');And then add an event listener to the ‘Get gists’ button:
document.getElementById('get-gists').addEventListener('click', getGists);This calls our main function, getGists():
function getGists(e) {
const btnGetGists = e.target;
btnGetGists.classList.add('fade'); // Fade out button
function error(err, container, e) {
console.error(err);
const escapedHTML = escapeHtml(`${err.status} ${err.statusText}: ${err.url}`);
container.innerHTML = `<div>${err.status} ${err.statusText}: ${err.url}</div>`;
show(container);
const button = e.target;
button.parentNode.removeChild(button);
}
fetch(
`https://api.github.com/users/${cfg.githubUser}/gists?per_page=${cfg.perPage}`
)
.then(function (response) {
if (response.ok) return response.json();
return Promise.reject(response);
})
.then(function (data) {
if (data.error) {
console.error(data.error);
return;
}
/**
* Pseudocode block 1: show listing of gists returned by API
*/
// Filter returned items to remove specific gists by ID
// Loop through filtered gists
// Get created date
// Get description
// Convert any URLs within description to links
// Transform backticked text to <code> elements
// Create <div> for gist with date, description and 'Get gist' button
// Add to button the gist ID as a `data` attribute
// End loop
// Add gists to DOM
// Fade in gists
/**
* Pseudocode block 2: show specific gist's content
*/
// Loop through 'Get gist' buttons in DOM
// Add on-click function
// Fetch 'https://api.github.com/gists/<gist-id>'
// Get gist type
// If type is text/html
// Escape the HTML
// If type is text/markdown
// Run the content through markdownit
// Add to DOM
// If text/markdown
// Add gist content in a <div>
// Else
// Add to UI in a code block
// Run code block through highlight.js
// End on-click function
// End loop
// Fade in gist
})
.catch((err) => {
error(err, gists, e);
});
}The fetch() function is the same in structure as the one we tested at the start of this post.
You’ll see a couple of blocks of pseudocode which run when the API call is successful. I find that writing such a high-level overview of the various steps in a process helps me think through a problem without getting bogged down in specifics. Now that we’ve outlined the main steps in pseudocode, we can convert them to real code:
// [...]
/**
* Show listing of gists returned by API
*/
const items = [];
// Filter returned items to remove specific gists by ID
const dataFiltered = data.filter(
(gist) => cfg.hideIds.indexOf(gist.id) === -1
);
for (let i = 0; i < cfg.gistsLimit; i++) { // Loop through filtered gists
if (dataFiltered[i]) {
// Get created date
const date = new Date(dataFiltered[i].created_at);
const dateFormatted = `${date.getDate()} ${
months[date.getMonth()]
}`;
const verb = !i ? 'Created ' : '';
const year = ` ’${date.getFullYear().toString().slice(-2)}`;
// Get description
let description = dataFiltered[i].description.trim().length
? `<div>${dataFiltered[i].description}</div>`
: '';
// Convert any URLs within description to links
description = description.replace(urlRegEx, function (match) {
return `<a href="${match}">${match}</a>`;
});
// Transform backticked text to <code> elements
description = description.replaceAll(/`(.+?)`/gi, function (match) {
return `<code>${match.slice(1).slice(0, -1)}</code>`;
});
// Create <div> for gist with date, description and 'Get gist' button
items.push(
`<div class="gist-container">
<h2><a href="${
dataFiltered[i].html_url
}">${
Object.keys(dataFiltered[i].files)[0]
}</a></h2> <span class="dt-published">${verb}${dateFormatted} ${year}</span>${description}
<button class="get-gist display-block button button-sm mt-1" data-gist-id="${
dataFiltered[i].id // Add to button the gist ID as a `data` attribute
}">Show</button>
<div id="gist-${dataFiltered[i].id}" class="gist-content hide fade"></div>
</div>`
);
} else break;
}
gists.innerHTML = items.join(''); // Add gists to DOM
btnGetGists.parentNode.removeChild(btnGetGists); // Remove 'Get gists' button
show(gists); // Fade in gists
/**
* Show specific gist's content
*/
// Loop through 'Get gist' buttons in DOM
const getGists = document.querySelectorAll('.get-gist');
getGists.forEach((getGistButton) => {
// Add on-click function
getGistButton.addEventListener('click', (e) => {
const gistId = e.target.dataset.gistId;
const btn = e.target;
btn.disabled = true; // Make sure user only triggers one API call
btn.classList.add('fade');
const el = document.getElementById(`gist-${gistId}`);
// Fetch 'https://api.github.com/gists/<gist-id>'
fetch(`https://api.github.com/gists/${gistId}`)
.then(function (response) {
if (response.ok) return response.json();
return Promise.reject(response);
})
.then(function (data) {
if (data.error) {
console.error(data.error);
el.innerHTML = `<div class="gist-content">${escapeHtml(data.error)}</div>`;
btn.parentNode.removeChild(btn);
show(el);
return;
}
const gistName = Object.keys(data.files)[0];
const gist = data.files[gistName];
let gistContent;
// Get gist type
if (gist.type === 'text/html') { // If type is text/html
gistContent = escapeHtml(gist.content); // Escape the HTML
} else if (gist.type === 'text/markdown') { // If type is text/markdown
const md = new markdownit('default', { html: true }); // Run the content through markdownit
gistContent = md.render(gist.content);
} else {
gistContent = gist.content;
}
// Add to DOM
if (gist.type === 'text/markdown') { // If text/markdown
el.insertAdjacentHTML( // Add gist content in a <div>
'beforeend',
`<div>${gistContent}</div>`
);
} else {
el.insertAdjacentHTML( // Add to UI in a code block
'beforeend',
`<pre class="code" role="code">${gistContent}</pre>`
);
hljs.highlightElement(el.querySelector('pre')); // Run code block through highlight.js
}
btn.parentNode.removeChild(btn);
show(el); // Fade in gist
})
.catch((err) => {
error(err, el, e);
});
});
});
// [...]Summary permalink
And that’s it! To summarise, we:
- used the GitHub API to fetch a listing and contents of public gists for a specific user
- created two proxy server scripts to authenticate with the GitHub API and fetch the data
- added a CORS directive to the proxy server to allow our calling domain to request data
- implemented basic caching to avoid unnecessary API data fetches
- added a couple of npm modules to tranform gists written in Markdown to HTML, and highlight the syntax of gists comprising code. The syntax highlighting module was a custom-built npm dependency to avoid serving the user unnecessary JavaScript
When creating a personal access token, if you only want to access public gists — as we do here — you don’t need to select any ‘scopes’: just name the token, choose an expiration date, and click ‘Generate token’. ↩︎
My home page isn’t popular enough to generate over 5,000 API requests an hour, but the GitHub documentation recommends checking headers for the last modification date before making requests for new data. I thought it was worth following best practice as if I was building a high-traffic feature, as I may be doing in future work. ↩︎